大数据,越大越好
Ray nella Sala
May 13, 2023
大数据作为一种归纳推理(详情在此)的应用,适用一个基本规则:有足够的观察,才能形成正确的结论。
理论上,这是无法实现的,David Hume 早已提出过这一质疑(也在那篇文章)。不过,当我们不得不面对现实世界时,这已是能做到的最好,而且目前已经取得了很多优质的成果。得益于逻辑学的创立,我们能够不断开发出许多更有力的数据处理方法,比如统计学及其诸多分支。现在,大数据也不例外。
与之前各种应用归纳推理的实用方法一样,大数据也要求大量的现实数据,以便生成一个针对某一问题的足够好的模型。然而,大量的现实数据本身就是问题。在大数据里,一个微小的神经网络也需要比较大的训练集;在统计学里,一个结论若想有效必须要有足够高的p值,而这来自现实依据的支撑。看这张表:
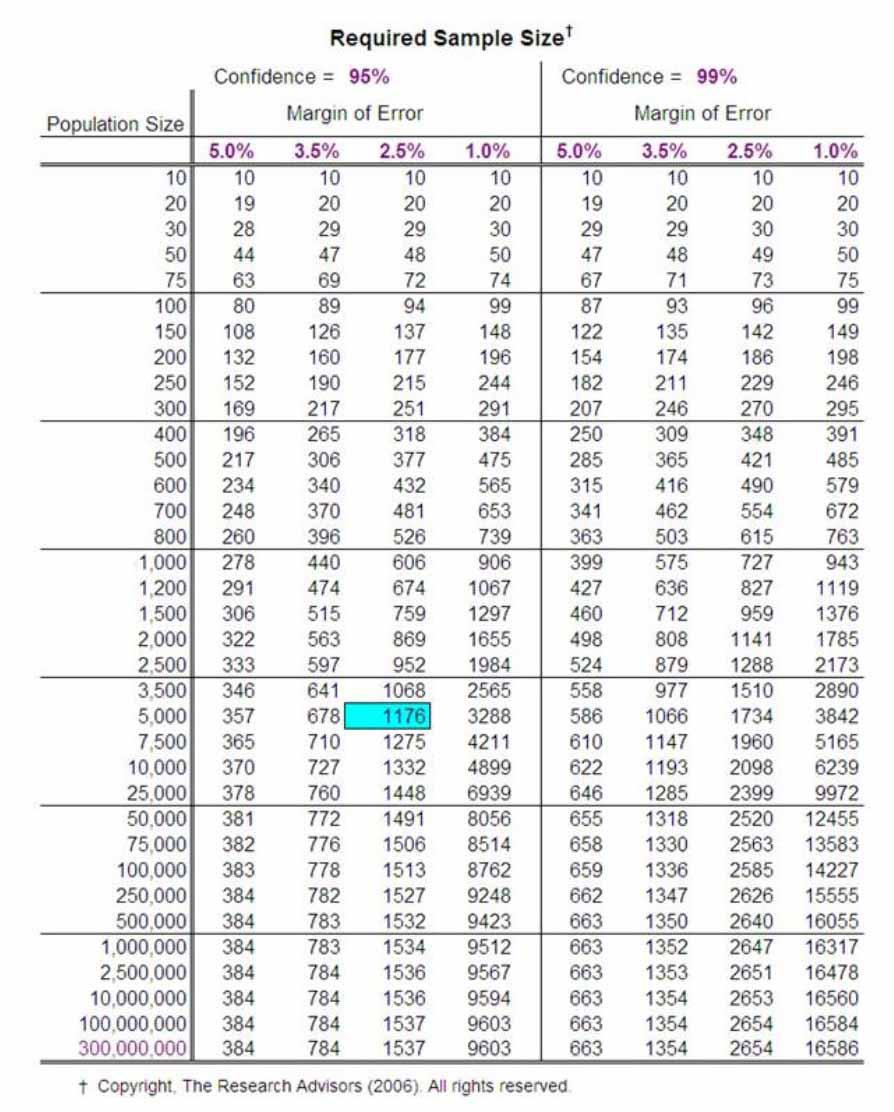
不需要仔细观察这些数字,只需要看到一个特征:若要置信水平提高,或误差范围缩小,必需样本容量扩大。另外,所得的结论可以覆盖更大的总体,更可能说明一个普遍的现象。
这张图说明了同样的问题:
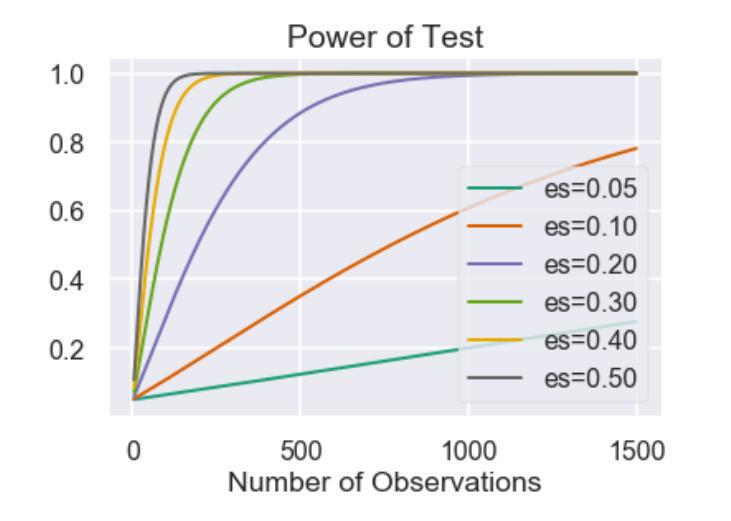
( y轴上的 Power of Test,测试的力度,是置信水平的泛用表达 )
事实上,在统计学之外,现实世界中的一切问题,无论大小,都需要相似的策略。例如 Johannes Kepler 发现天体运行规律的故事。在 『Deep Learning with PyTorch』 里,为了讲清 『学习』 这个词的含义,这个故事被详细描述。在开普勒学习天体运行的过程中,第一步便是 『收集许多有效数据』。其实这是任何学习过程的第一步。(仅限于自然科学。哲学或数学这些理论科学,需要的是演绎推理,是一个完全不同的过程。)
当我们说起 『数据』 的时候,我们大概是在指 『信息』。从数据到信息的处理过程与这篇文章关系不大,关键在于数据是信息的必要条件。『有效的结论』 指的是 『知识』,因为知识来源于大量有效结论的累积。在 Hendrik Willem van Loon 所作的『宽容』这本书里,用 Socrates 的故事论述了信息的重要:
『只要一个人明辨是非,没有朋友的赞赏,没有金钱,没有家庭甚至没有亲人,仍能成事。但如果没有对每一个问题彻底地权衡利弊,没有人可能得出正确的结论。因此,人们必须拥有讨论一切的完全自由,不能被官方干涉。』
我不知道这是否是 Socrates 的原话(尽管 van Loon 这么说,但是我没找到其他佐证),但是这段话的价值在于内容,不在于说者。『数据』 本身作为外在的存在物(具体地说,是其他存在物的属性或特征),可以用来转化成信息。所得信息的质量首先在于数据的量的积累,在这之前就评价数据的质(好坏/真伪/有效性)没有任何意义。诚然,更多的数据并不一定表示更真实的信息,因为数据中包含错误信息的可能性总是存在的。然而更多的数据仍然是符合逻辑的选择。如果确实有数据传达了错误的信息,只有收集更多的其他来源的数据才有更可能抵消这些错误信息的误导。简单地说,拥有越多的数据,思维就越不可能受限。
问题的关键在于,『好/坏/利/害』 都是人们对数据的评价。然而数据本身作为外在的存在物,与任何人的主观无关。人们根据自己的道德准则对数据做出评价,这些准则可能来自于他们的个人经验、社会环境,所受教育,或者上级命令,然而外在的存在物不会因此有丝毫改变。我只应关注外在的存在物,而非其他人的主观,无论这些人的身份地位以及数量。
由此可以得出之前说的『宽容』里那段话的主题。交流是数据交换以及信息传播的关键,如果交流被干扰或者被过滤,人们就更有可能陷入无知,从而非常容易被操纵。借用 George Orwell 在 『1984』 中给出的总结:『谁控制了过去就能控制未来,谁控制了现在就能控制过去。』
题外话,这也可能解释了为什么视野宽广的人可能更明智。因为他们能从自己的视野范围里获得更多数据,让自己的思维和认知(『头脑中的神经网络』)得到更充分的训练。所以人们都需要站在更高处,以便得到更宽广的视野。
所以,对于我,理智的做法就是收集更多的数据,以便对周围事物有(可能)更清楚的认知。对于摆在面前的任何问题,恐怕都需要更多数据,才能找到更明智的答案。借用一则成语:『兼听则明,偏信则暗。』
0 people liked this.
0 / 960